Claude 4.5 Opus가 76.8%로 1위를 차지한 SWE-bench 2026년 2월 최신 결과. 상위 10개 AI 모델의 코딩 성능과 중국 AI의 약진을 분석합니다.
SWE-bench 2026년 2월 리더보드: AI 코딩 모델 성능 비교 분석
핵심 요약
- Claude 4.5 Opus가 76.8%로 1위: SWE-bench Verified 데이터셋에서 가장 높은 해결률 달성
- 중국 AI의 약진: MiniMax M2.5, GLM-5, DeepSeek V3.2 등 상위 10위권 진입
- 공정한 비교: 모든 모델이 동일한 시스템 프롬프트로 테스트되어 객관적 성능 평가 가능
- Verified 벤치마크 기반: OpenAI가 수동으로 선별한 500개 샘플의 정제된 테스트셋 사용
- 실전 코딩 능력 측정: 12개 오픈소스 저장소의 2,294개 실제 버그 픽스 사례 포함
SWE-bench란? 소프트웨어 엔지니어링 AI의 새로운 표준
SWE-bench는 AI 모델의 실전 소프트웨어 개발 능력을 측정하는 벤치마크로, 최근 AI 연구소들이 새로운 모델을 출시할 때 가장 즐겨 언급하는 지표입니다. 단순한 이론적 능력 측정을 넘어 실제 오픈소스 프로젝트의 버그를 얼마나 잘 해결할 수 있는지를 평가합니다.
이번 2026년 2월 업데이트는 특별한 의미를 가집니다. 공식 리더보드가 자주 업데이트되지 않는 가운데, 최근 현 세대 모델들을 대상으로 완전한 테스트를 완료했기 때문입니다. 무엇보다 중요한 점은 이 벤치마크 결과가 연구소들이 직접 보고하지 않은 객관적 성능 평가라는 것입니다.
Verified 버전의 중요성: 이번 테스트에 사용된 것은 원본 SWE-bench가 아닌 SWE-bench Verified 입니다. 이는 OpenAI의 지원을 받아 수동으로 정제된 500개 샘플로 구성된 서브셋으로, 데이터의 품질과 신뢰성이 보장됩니다. 원본 데이터셋의 2,294개 사례에서 엄선된 것이므로, 더욱 의미 있는 성능 비교가 가능합니다.
테스트에 사용된 mini-swe-bench 에이전트 는 약 9,000줄의 Python 코드로 구성되었으며, 표준화된 프롬프트 설정으로 모든 모델에게 동등한 조건을 제공했습니다. 이는 공정한 비교를 위해 매우 중요한 요소입니다.
2026년 2월 최신 성적: Claude 4.5 Opus의 압도적 우위
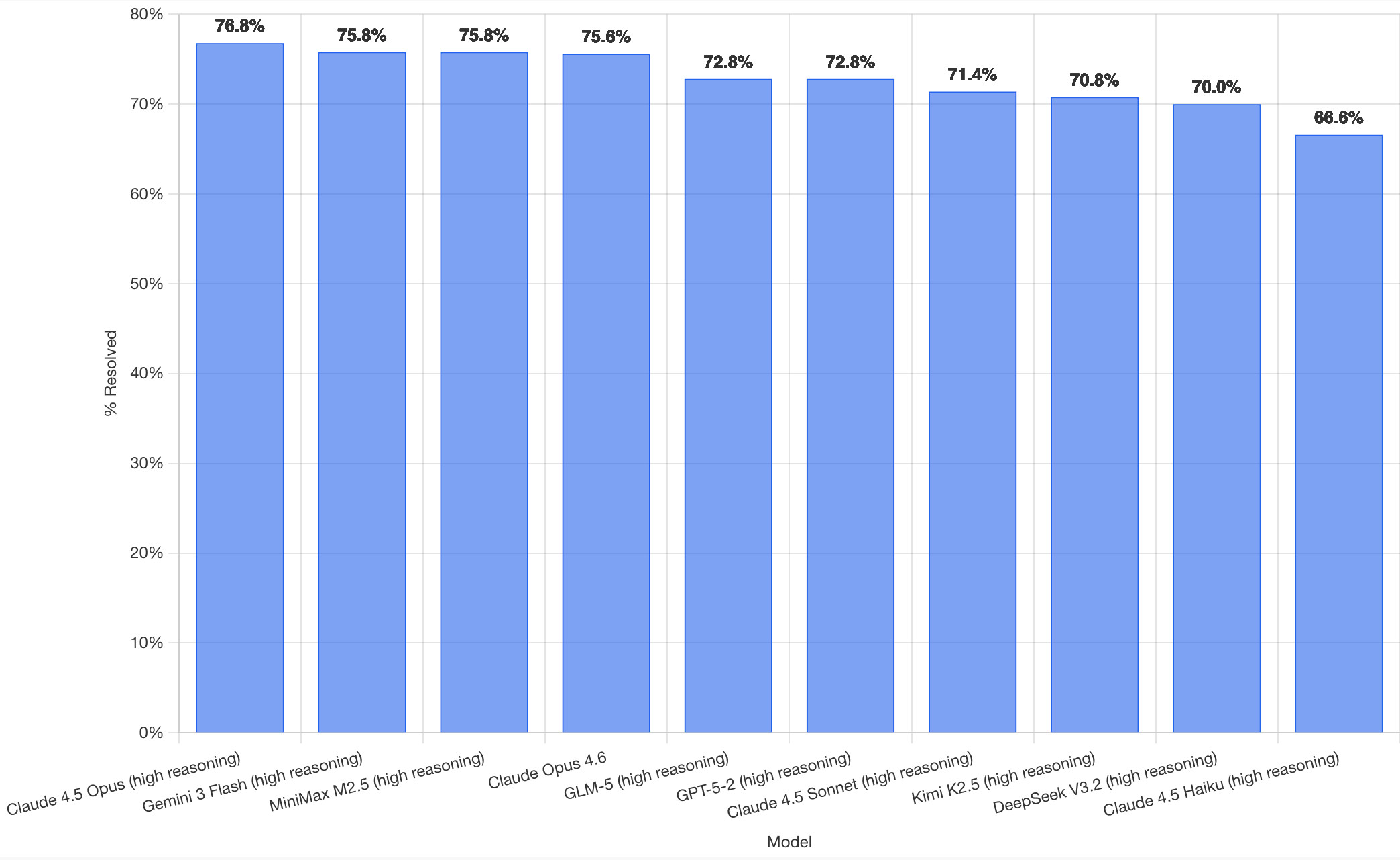
최신 리더보드에서 가장 주목할 점은 Claude 4.5 Opus의 76.8% 해결률 로, 이는 상위 10개 모델 중 가장 높은 성능입니다. Anthropic의 최신 모델이 소프트웨어 엔지니어링 작업에서 확실한 우위를 보여주고 있습니다.
흥미롭게도 Claude 4.5 Opus는 자사의 다른 플래그십 모델인 Claude Opus 4.6을 약 1%포인트 차이로 앞섭니다. 4.5 버전이 더 최적화되어 있거나, 코딩 작업에 더 적합한 성능을 보여주고 있다는 의미입니다. Claude Opus 4.6은 75.6%로 4위에 랭크되었습니다.
상위 10개 모델의 성능 순위:
- Claude 4.5 Opus - 76.8%
- Gemini 3 Flash - 75.8%
- MiniMax M2.5 - 75.8%
- Claude Opus 4.6 - 75.6%
- GLM-5 - 72.8%
- GPT-5.2 - 72.8%
- Claude 4.5 Sonnet - 72.8%
- Kimi K2.5 - 71.4%
- DeepSeek V3.2 - 70.8%
- Claude 4.5 Haiku - 70.0%
Anthropic의 Claude 시리즈가 상위 10개 중 4개 모델을 차지 하는 것은 주목할 가치가 있습니다. 이는 코딩과 소프트웨어 엔지니어링 작업에서 Claude 라인업이 얼마나 강력한지를 보여줍니다.
중국 AI 기업의 약진: 글로벌 시장 경쟁 심화
이번 벤치마크 결과에서 가장 놀라운 변화는 중국 AI 기업들의 약진 입니다. MiniMax, Alibaba, DeepSeek 등 중국 연구소의 모델들이 상위 10위권에 여러 개 진입했습니다.
MiniMax M2.5 는 지난주 출시된 229B 규모의 모델로 75.8%의 해결률을 기록하며, Gemini 3 Flash와 동등한 수준의 성능을 보여주고 있습니다. 이는 매우 인상적인 성과입니다. 모델 규모가 Claude나 Gemini 같은 대규모 모델보다 작으면서도 이러한 성능을 달성했다는 것은, MiniMax의 기술력과 최적화 능력이 뛰어나다는 것을 의미합니다.
GLM-5 는 Alibaba의 모델로 72.8% 해결률로 5위를 차지했습니다. Kimi K2.5 는 71.4%로 8위에, DeepSeek V3.2 는 70.8%로 9위에 랭크되었습니다. 이렇게 3개의 중국 모델이 상위 10위권에 진입한 것은 중국의 AI 개발 역량이 글로벌 수준에 도달했음을 시사합니다.
이러한 약진은 AI 산업의 지정학적 구도 변화를 반영합니다. 더 이상 코딩 작업은 미국 기업(OpenAI, Google, Anthropic)의 독무대가 아니게 되었습니다. 중국 기업들도 충분히 경쟁 가능한 수준의 모델을 개발하고 있으며, 특정 영역에서는 오히려 더 우수한 성능을 보여주고 있습니다.
OpenAI와 Google의 성적 분석: 기대와 현실의 간극
OpenAI의 GPT-5.2 는 72.8%의 해결률로 6위에 랭크되었습니다. 하지만 주목할 점은 OpenAI의 최고 코딩 모델로 알려진 GPT-5.3-Codex가 포함되지 않았다 는 것입니다. 이는 아마도 해당 모델이 아직 OpenAI API에서 공식적으로 제공되지 않기 때문으로 추측됩니다.
Google의 Gemini 3 Flash 는 75.8%로 2위를 기록했습니다. Flash 시리즈의 가벼운 모델임을 감안하면, 이는 매우 인상적인 성과입니다. Google은 최신 Gemini 라인업에서 성능과 효율성의 좋은 균형을 이루었습니다.
Claude 4.5 Sonnet은 72.8%로 7위에 랭크되었으며, Claude 4.5 Haiku는 70.0%로 10위를 차지했습니다. Anthropic은 모델 크기별로 일관된 성능 향상을 보여주고 있으며, 심지어 가장 가벼운 Haiku 모델도 상위 10위권에 진입했습니다.
벤치마크의 제한사항: 공정한 비교의 의미와 한계
이 벤치마크가 공정하다는 점은 큰 장점입니다. 모든 모델이 동일한 시스템 프롬프트 를 사용하여 테스트되었기 때문입니다. 이는 하드웨어 차이, 프롬프트 엔지니어링 수준, 또는 특정 모델에 최적화된 설정 등의 요인을 배제하고 순수한 모델 성능을 비교할 수 있게 해줍니다.
그러나 이것이 곧 완벽한 비교라는 의미는 아닙니다. 현실의 소프트웨어 개발 환경에서는 다양한 도구와 최적화된 프롬프트가 사용 됩니다. 각 모델별로 맞춤형 하네스를 구축하거나 특화된 프롬프트를 사용하면 성능이 달라질 수 있습니다.
예를 들어, OpenAI의 o1이나 Claude의 extended thinking 같은 고급 추론 기능을 활용하면, 또는 모델별로 최적화된 코딩 프롬프트를 사용하면, 이 벤치마크 결과와는 다른 순위가 나올 수 있습니다. 따라서 이 결과는 "표준화된 조건에서의 성능 비교"로 해석해야 하며, "모든 상황에서의 절대적 우위"로 읽어서는 안 됩니다.
SWE-bench Verified는 500개의 정교하게 선별된 문제로 구성되어 있어 데이터 품질은 높습니다만, 실제 소프트웨어 개발 프로젝트의 다양한 난이도와 유형을 모두 대표하지는 못합니다. 따라서 이 벤치마크는 AI 코딩 모델의 일반적인 능력을 비교하는 좋은 지표 이지만, 특정 조직이나 프로젝트에 어떤 모델이 최고인지를 결정하는 유일한 기준이 되어서는 안 됩니다.
Claude for Chrome을 활용한 차트 분석 자동화
흥미로운 추가 사항으로, 위의 차트는 원본 SWE-bench 웹사이트 스크린샷이지만, 원래 차트에는 막대별 정확한 백분율 값이 표시되지 않았습니다. 이 데이터를 추출하기 위해 Claude for Chrome 이라는 브라우저 자동화 도구가 활용되었습니다.
Claude for Chrome을 사용하여 다음과 같은 작업을 수행했습니다:
- SWE-bench 웹사이트 자동 접속
- "Compare results" → "Select top 10" 메뉴 자동 선택
- 차트에 백분율 값을 표시하는 커스텀 JavaScript 주입
- Chart.js 캔버스 컨텍스트를 활용하여 각 막대 위에 백분율 레이블 동적 추가
이 과정은 매우 효율적으로 작동했으며, Claude는 재귀 문제를 피하기 위해 Playwright로 전환하는 등 기술적 문제들을 자동으로 해결했습니다. 이는 AI 에이전트가 정보 추출과 데이터 시각화 작업에서 얼마나 효과적 일 수 있는지를 보여주는 좋은 사례입니다.
실제 JavaScript 코드 예시:
meta.data.forEach((bar, index) => {
const value = dataset.data[index];
if (value !== undefined && value !== null) {
ctx.save();
ctx.textAlign = 'center';
ctx.textBaseline = 'bottom';
ctx.fillStyle = '#333';
ctx.font = 'bold 12px sans-serif';
ctx.fillText(value.toFixed(1) + '%', bar.x, bar.y - 5);
}
});
이러한 자동화 기술은 데이터 기반 의사결정이 필요한 현대 조직에서 매우 유용합니다. 수동으로 차트에서 값을 읽어내거나 스크린샷을 편집하는 대신, AI 에이전트가 자동으로 필요한 정보를 추출하고 시각화할 수 있게 된 것입니다.
2026년 AI 코딩 모델 선택 가이드
이 벤치마크 결과는 소프트웨어 엔지니어와 개발 팀이 AI 코딩 모델을 선택할 때 참고할 수 있는 중요한 지표입니다.
최고 성능이 필요한 경우: Claude 4.5 Opus를 선택하면 76.8%의 벤치마크 성능으로 가장 높은 해결률을 기대할 수 있습니다.
비용 효율성이 중요한 경우: Claude 4.5 Haiku (70.0%), Claude 4.5 Sonnet (72.8%), Gemini 3 Flash (75.8%) 등 가벼운 모델도 충분히 경쟁력 있는 성능을 제공합니다.
다양한 옵션 검토: 중국 모델들의 성과를 고려하면, MiniMax M2.5나 GLM-5 같은 대안도 검토할 가치가 있습니다. 비용, 지연시간, 데이터 거주 요구사항 등 벤치마크 점수 외의 요소들도 함께 고려해야 합니다.
프로젝트별 맞춤 평가: 이 벤치마크는 일반적인 코딩 작업을 기준으로 하므로, 자신의 프로젝트에 특화된 작은 규모의 테스트 실행을 권장합니다.
결론
2026년 2월의 SWE-bench 리더보드 업데이트는 AI 코딩 모델 시장이 빠르게 진화하고 있음을 보여줍니다. Claude 4.5 Opus의 압도적 성능, 중국 AI 기업들의 약진, 그리고 표준화된 벤치마크를 통한 객관적 평가가 이루어진 점은 모두 주목할 가치가 있습니다. 개발자와 조직들은 이러한 데이터를 바탕으로 자신의 필요에 가장 적합한 AI 모델을 선택할 수 있게 되었습니다. AI 코딩 역량이 점점 더 중요해지는 시대에, 이번 벤치마크 결과는 현재 시점에서의 각 모델의 강점과 경향을 파악하는 데 매우 유용한 참고 자료입니다.
Original source: SWE-bench February 2026 leaderboard update
powered by osmu.app